Analyse and compare costs
The analyses of the submitted cost data is automated and based on mathematical models and restrictions that are further explained in this page. The analyses serve two purposes. The first is to be able to produce diverse results that are interesting to the stakeholders. The second is to understand cost data, to learn how tostructure it and to learn which parameters are needed in order to better understand and compare data as well as build cost concept model.
A word on precision and significant figures
There are a number of factors that affect the potential precision of the figures used in calculations. Due to the nature of the domain and the objectives of the Cost Comparison Tool, the accuracy of the submitted costs (which are mapped into normalised categories) as well as those generated as part of the comparison of costs with other groups and peers must be performed with limited precision and interpreted with caution. The information requested from the users should always be seen through the lens of ‘rough numbers’. The objective of the curation cost comparison is to guide users towards strategies that could potentially reduce the cost of their curation through giving a general idea of how they compare with others, and not to serve as a precise tool to evaluate and compare costs. It would perhaps be better to describe the figures as plausible as opposed to precise. Examples of this reduction in precision are:
- the smallest available units for data volume and date intervals, which go down to Gigabyte and Year and not smaller.
- lack of support for partial numbers (only positive integers are supported) for data volume, date intervals, and costs
- the main mapping tool into categories is the slider, which goes into integer steps on a percentage scale
To avoid misleading precision, the processed information that goes back to the user is rounded to the maximum number of significant figures. As the least precise input data tool is the slider, which is used both on asset types distribution and on cost data mapping into categories, it was calculated that the maximum number of significant figures is 2. Therefore, all mapped costs and asset type data volumes are rounded to 2 figures (e.g. 12345 is rounded to 12000, 0.0012345 is rounded to 0.0012).
Currency conversion and reasons for common currency on output
Costs can be entered using various currencies, as every organisation can select the currency they use on their profile. The costs are entered within a cost data set and cost data sets have defined date intervals. Conversion rates between two currencies change often but we have chosen to use a single rate for each year. In addition, conversion rates are not transitive. In other words, converting from currency A to B is not the same as converting A to C and then C to B. Due to these two issues, and to reduce error and provide coherent results to all users independently of their currency, the output results are always presented in Euros (which is the common currency for output results, selected by the 4C partners).
Costs are converted into Euros when they are entered, providing to the users feedback as they are entering the information. The conversion into Euros is made using the average conversion rate for the years that the cost applies. Yearly conversion rates from supported currencies into Euros are defined on an administrative page within the system, and more currencies and conversion rates can be easily added. On the first released version, yearly conversion rates for British pound and US dollar for the last 15 years (from 1998) were added. If costs are added from a date interval for which no yearly rate exists, the rate for the closest year is used. If yearly rates are changed or added after cost data for that year is entered, converted values are re-calculated.
Concept and calculation of relative costs
To make the costs between organisations of different sizes comparable, the concept of relative cost must be introduced. This tries to provide a value that is independent of variables that significantly affect the value, such as data volume and the date interval applied to the cost data set. The currently selected relative cost definition is cost (in Euros) per Gigabyte per Year (€/GB/Y). T his value is calculated by dividing the cost value, converted into Euros, by the data volume in Gigabytes and then by the duration in years for which the cost data set applies.
Calculation of combined cost data sets
In the combined output results sections—My costs, Group comparison and Peer comparison—information from several cost data sets can be combined into a single distribution of relative costs of the defined categories. The costs to be combined can be filtered using the options of those areas. Mapped relative costs ( x̅ ) from different cost data sets ( x ) are combined using a weighted arithmetic mean formula (below), where the weight (w) is the data volume.
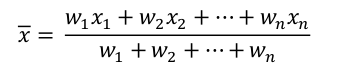
With this formula, costs from cost data sets with a bigger data volume have more importance on the final combined value. On group comparison, costs from the selected groups are combined with the same formula using all cost data sets from all organisations that fit the selected group profile.
Calculation of peer similarity
The similarity score between peers, shown in the peer comparison area, is calculated by comparing a set of fields from organisation profile and cost data set information, each with a configurable weight that can be changed on the administration pages of the system.
The set of fields used and their default weight value are:
- Organisation type (weight 50)
- Data volume (weight 40)
- Main asset type (weight 20)
- Number of copies (weight 20)
- Staff size (weight 20)
- Scope (weight 10)
The weighted arithmetic mean formula is used to calculate and assign ‘similarity’ into the following levels:
- Super similarity (80-100% similarity)
- Very high similarity (70-80% similarity)
- High similarity (60-70% similarity)
- Medium similarity (40-60% similarity)
- Lower similarity (0-40% similarity)
For the organisation type, the weight of the field is multiplied by the percentage of match between types of the user organisation with the organisation that you are comparing. In this case the score is maximum, (or rather it is equal to the weight of the field) when the organisations have the same types. The score of the data volume, number of copies and staff size fields is calculated in a similar fashion. The weight of the fields is multiplied by the percentage of difference36 between the weighted average of corresponding field in both organisations. Similar weighted averages will result in closest scores to the weight of field. The score of the main asset type and scope fields is calculated in a similar way. The weight of the fields is multiplied by the percentage of match between the set of values of field for each organisation. The percentage of similarity between two organisations is calculated doing the ratio between the calculated score and the maximum score.